Serialisierung
Das Problem
- Wie transportiere ich Java Objekte über das Netzwerk?
- Wie schreibe ich Java Objekte in Dateien?
- Wie lese ich Java Objekte aus Dateien?
- Wie gehe ich mit ganzen Netzen von Objekten um?
In der Objektorientierten Programmierung entstehen schnell Netze von miteinander verbundenen Objekten. Wenn man diese über die Grenzen des Programms transportieren möchte, muss man das gesamte Netz durchlaufen, die Daten extrahieren und speichern. Beim Einlesen muss man aus den Daten die Objekte und ihre Beziehungen rekonstruieren. Dies kann – abhängig von der Größe des Objektnetzes – sehr aufwändig und kompliziert werden.
Es gibt generell zwei Gründe, warum man Objekte aus einem Java-Programm heraus holen möchte
- Man möchte die Daten an ein weiteres Java-Programm übergeben, dass zum selben Zeitpunkt läuft (Marshalling). Ein Beispiel wäre hier die Kommunikation über ein Netzwerk.
- Man möchte die Daten speichern und später wieder in dasselbe Programm laden (Persistenz).
In beiden Fällen muss man die komplexen Objektstrukturen im Speicher in eine einfache, zusammenhängende Folge von Bytes konvertieren. Da man hierbei die über Referenzen verbundenen, im Speicher nicht zusammen liegenden Daten hintereinander schreibt spricht man von Serialisierung. Die umgekehrte Operation, also den Aufbau der Objekte aus der linearen Folge von Bytes, nennt man Deserialisierung.
Die Lösung: Java Serialisierung
- Mit
DataOutputStreamundDataInputStreamkann man Objekte in Streams schreiben und aus ihnen lesen, man muss aber die gesamte Logik von Hand schreiben - Java-Serialisierung übernimmt dies automatisch und schreibt ganze Objektgeflechte
- Grundlegende Klassen
ObjectOutputStream- Schreiben von Objekten (Serialisierung)ObjectInputStream- Lesen von Objekten (Deserialisierung)- Serialisierung ist relativ robust gegen Änderungen an den Objekten, sodass serialisierte Objekte auch nach Änderung an der Klasse (häufig) noch deserialisiert werden können
Erfreulicherweise ist in Java bereits ein Mechanismus eingebaut, der es erlaubt, Objektnetze direkt in einen beliebigen Stream (Datei, Netzwerk etc.) zu schreiben. Die zentrale Klassen hierzu sind ObjectOutputStream und ObjectInputStream. Als Filter sind sie in der Lage, jeden anderen Stream als Quelle bzw. Senke der serialisierten Daten zu verwenden.
Regeln für die Serialisierung
- Objekte können nur serialisiert werden, wenn ihre Klassen
java.io.Serializableimplementieren - Superklassen müssen entweder selbst
java.io.Serializableimplementieren oder einen Default-Konstruktor haben - Wenn die normale Serialisierung nicht ausreicht kann man mit
java.io.Externalizableein völlig eigenes Protokoll implementieren
Serialisierung kann Sicherheitslücken schaffen, wenn man in der Lage wäre jedes beliebige Objekt gegen seinen Willen zu serialisieren. So könnte man z. B. ein User-Objekt, das die Berechtigungen des Benutzers im Programm repräsentiert serialisieren, verändern und neu laden. Weiterhin gibt es Objekte, die sich aus logischen Gründen nicht serialisieren lassen: ein Thread ergibt später oder in einer anderen Java VM genauso wenig einen Sinn, wie eine geöffnete Datei oder eine Netzwerkverbindung.
Der Einzige der entscheiden kann, ob Serialisierung erlaubt werden soll oder nicht ist die Klasse von der das zu serialisierende Objekt erzeugt wurde. Diese kann durch Implementierung des Interfaces Serializable anzeigen, dass ihre Objekte serialisiert werden dürfen. Das Interface hat selbst keine Methoden (Tagging-Interface oder zero abstract method interface) und dient nur dazu, die Klasse zu kennzeichnen.
Die Superklassen einer serialisierbaren Klasse müssen nicht zwingend selbst serialisierbar sein, sondern es reicht, wenn sie einen Default-Konstruktor haben. Eine andere Forderung wäre unlogisch, denn sonst müsste Object selbst serialisierbar sein und würde diese Eigenschaft (wegen der Transitivität der Implements-Beziehung) an alle Java-Klassen vererben, womit dann doch wieder jedes Java-Objekt serialisierbar wäre.
Wenn die Möglichkeiten der Serialisierung nicht ausreichen, kann man über das Interface Externalizable noch weiter in die Abläufe der Serialisierung eingreifen. Eine Behandlung würde aber hier den Rahmen sprengen.
Beispiel: Serialisierung
Manager m = new Manager("Hans Alberts", 10000.0,
new Date(0x2222222222L), "Buchhaltung");
ObjectOutputStream os = new ObjectOutputStream(
new FileOutputStream("/tmp/albert.ser"));
os.writeObject(m);
os.close();
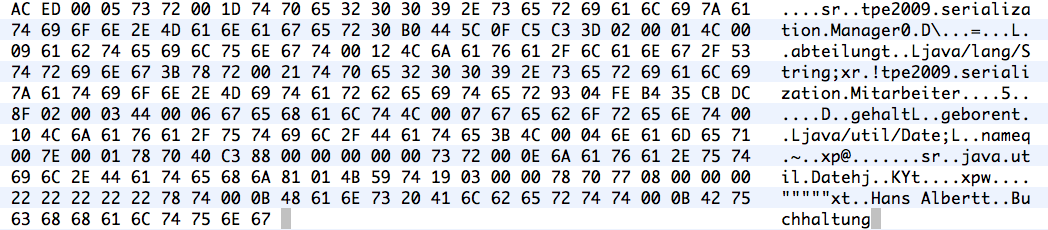
Das Beispielprogramm legt ein Objekt vom Typ Manager an. Um dieses dann zu serialisieren, wird ein ObjectOutputStream angelegt. Da dieser zwar die Objekte serialisieren kann aber als Filter-Stream selbst nicht persistieren oder versenden, wird ein FileOutputStream für die eigentliche Speicherung verwendet.
Das Schreiben des Objektgeflechts erfolgt durch den Aufruf der Methode writeObject() des ObjectOutputStream. Hierdurch werden alle Objekte, die von der Referenz m aus erreichbar sind, gespeichert. Konkret in diesem Beispiel, der Manager selbst, zwei Strings und ein Date-Objekt.
Beispiel: Deserialisierung
ObjectInputStream is = new ObjectInputStream(
new FileInputStream("/tmp/albert.ser"));
Manager albert = (Manager) is.readObject();
is.close();
System.out.println(albert.getDetails());
Hans Alberts, geb. am Sat Aug 24 19:39:10 CET 1974 hat ein Gehalt von
10000.0 und leitet die Abteilung Buchhaltung
Die Deserialisierung erfolgt analog zur Serialisierung. Mithilfe eines ObjectInputStreams und eines darunterliegenden FileInputStreams werden die Objekte aus der Datei eingelesen und ein neues Objekt vom Typ Manager wird angelegt. Da die Methode readObject() den Rückgabetyp Object hat, muss die Referenz noch auf Manager gecastet werden. Die Ausgabe zeigt, dass tatsächlich wieder dieselben Daten im Objekt enthalten sind.
Objektgeflecht und Serialisierung

Obwohl man der writeObject()-Methode nur eine einzige Referenz übergibt, werden bei der Serialisierung alle Objekte gespeichert, die von dieser Referenz aus erreichbar sind. Man sagt auch, dass die gesamte transitive Hülle (transitive closure) serialisiert wird. Dies ist nötig, da die Deserialisierung an einer ganz anderen Stelle zu einer ganz anderen Zeit passieren kann (z. B. bei einem gespeicherten Spielstand nach Wochen). Nur wenn man alle erreichbaren Objekte mit speichert, erhält man später ein korrektes Objekt-Modell.
Damit verhält sich Serialisierung anders als die clone()-Methode von Object. Während clone() nur eine flache Kopie (shallow copy) erzeugt, bekommt man durch eine Serialisierung und anschließende Deserialisierung eine tiefe Kopie (deep copy).
Transiente Attribute
- Serialisierung erfasst alle Felder, manche Objekte können aber nicht serialisiert werden
- Mit dem Schlüsselwort
transientkann man einzelne Attribute von der Serialisierung ausnehmen (transiente Attribute)
Wie bereits oben erwähnt, gibt es einige Klassen, deren Objekte gespeichert oder übertragen sinnlos sind, z. B. Threads, geöffnete Dateien, Netzwerkverbindungen etc. Wenn diese in einem Objektgeflecht auftauchen, kann das ganze Gebilde nicht serialisiert werden. Es würde also eine einzige nicht serialisierbare Klasse ausreichen, damit das Speichern fehlschlägt. Um dieses Problem zu umgehen, gibt es die Möglichkeit, Attribute einer Klasse mit dem Schlüsselwort transient zu kennzeichnen. Diese Attribute werden bei der Serialisierung ignoriert und bei der Deserialisierung mit den entsprechenden Default-Werten (null, 0, false) belegt. Außerhalb der Serialisierung verhalten sich transiente Attribute ganz normal.
Beispiel: Transiente Felder
public class A implements Serializable {
private String s1;
private String s2;
private transient String s3;
public A(String s1, String s2, String s3) {
if ((s1 == null) || (s2 == null) || (s3 == null)) {
throw new NullPointerException();
}
this.s1 = s1;
this.s2 = s2;
this.s3 = s3;
}
@Override
public String toString() {
return String.format("A [s1=%s, s2=%s, s3=%s]", s1, s2, s3);
}
}
Im Beispiel ist das Attribut s3 der Klasse A als transient gekennzeichnet. Weiterhin ist der Konstruktor so gestaltet, dass man keine Objekte anlegen kann, bei denen eines der Attribute null ist. Eine toString()-Methode gibt den Inhalt des Objektes aus.
// Object schreiben
ObjectOutputStream os = new ObjectOutputStream(
new FileOutputStream("/tmp/transient.ser"));
os.writeObject(new A("String1", "String2", "String3"));
os.close();
// Object lesen
ObjectInputStream is = new ObjectInputStream(
new FileInputStream("/tmp/transient.ser"));
A a = (A) is.readObject();
is.close();
System.out.println(a);
A [s1=String1, s2=String2, s3=null]
Wenn man ein Objekt vom Typ A serialisiert und danach wieder deserialisert, erhält man eine tiefe Kopie. Die Ausgabe zeigt, dass das Attribut s3 tatsächlich nicht gespeichert wurde und anstatt des Wertes „String3“ jetzt den Wert null hat. Das Schlüsselwort transient am Attribut s3 hat also bewirkt, dass s3 bei der Serialisierung ignoriert und bei der Deserialisierung auf null gesetzt wurde.
Das Ergebnis ist insofern überraschend, als dass der Konstruktor von A es gar nicht zulässt, Objekte zu erzeugen bei denen eines der Attribute null ist. Die Ausgabe zeigt aber deutlich, dass genau dies für s3 der Fall ist. Dieses seltsame Verhalten klärt sich, sobald man versteht, dass Serialisierung die Objekte nicht auf gewöhnlichem Wege erzeugt. Genauso wie das Clonen, geschieht die Erzeugung von Objekten bei der Deserialisierung am Konstruktor vorbei und passiert direkt im Speicher der VM. Somit sind Prüfungen durch den Konstruktor irrelevant, weil er überhaupt nicht aufgerufen wird.
Eigene Formate für die Serialisierung
- Viele effiziente Speicherstrukturen (z. B. verkettete Listen) sind in der serialisierten Form nicht mehr kompakt
- Mit
readObject()undwriteObject()kann jede Klasse in die Serialisierung eingreifen
Eine doppelt verkettete Liste ist eine sehr effiziente Struktur im Hauptspeicher, wenn man häufig Elemente einfügen und entfernen muss. Sie verwendet zwar mindestens drei Referenzen pro Element, dieser Speicherverbrauch wird aber in den meisten Fällen durch die Gewinne beim Verarbeiten der Listenelemente aufgewogen.
Serialisiert man eine verkettete Liste, so blähen sich die Daten erheblich auf. Neben den eigentlichen Nutzdaten wird die Struktur der Liste (einschließlich aller Referenzen) gespeichert, obwohl es genügen würde nur die Daten zu speichern, da in der serialisierten Form kein Bedarf am Einfügen oder Löschen von Elementen besteht und sowieso ein Element auf das nächste folgt.
Um Datenstrukturen effizient serialisieren zu können, bietet Java die privaten Methoden writeObject() und readObject() an. Diese werden – so vorhanden – bei der Serialisierung gerufen und erlauben es der Klasse anzugeben, in welchem Format sie am besten serialisiert werden sollte.
Beispiel: readObject() und writeObject()
class Element implements Serializable {
Element next;
String daten;
Element(String daten) {
this.daten = daten;
}
}
public class Liste implements Serializable {
Element erstes;
Element aktuelles;
public Liste add(String daten) {
if (erstes == null) {
erstes = new Element(daten);
aktuelles = erstes;
} else {
Element neu = new Element(daten);
aktuelles.next = neu;
aktuelles = neu;
}
return this;
}
}
Das Beispiel zeigt eine sehr primitive, einfach verkettete Liste. Für jeden Eintrag in der Liste wird ein Objekt vom Typ Element verwendet. Die Liste kennt das erste und letzte Element und hat im vorliegenden Beispiel nur eine einzige Methode zum Anfügen von Elementen.
Wenn man diese Liste serialisiert, entstehen große Datenmengen, wie der folgende Auszug zeigt.
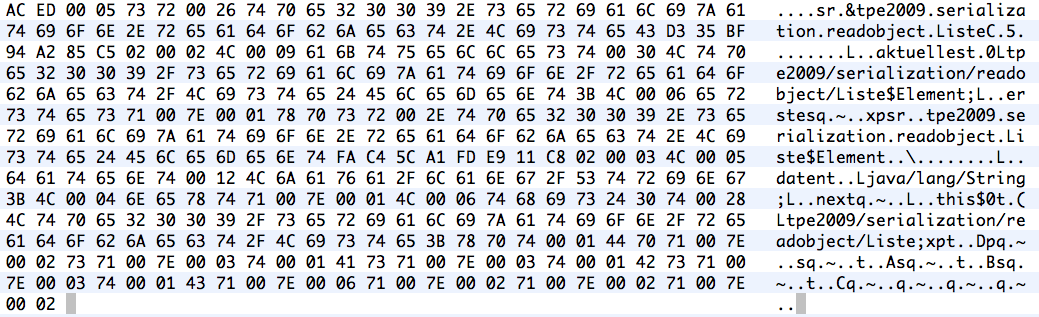
Für jedes Elemente der Liste werden nicht nur die Referenzen, sondern auch noch der Datentyp als String gespeichert. Die Datenmenge explodiert.
Man kann diesem Problem aber begegnen, wenn man die Liste in die Serialisierung eingreifen lässt. Der folgende Quelltext zeigt wie.
public class Liste implements Serializable {
transient Element erstes;
transient Element aktuelles;
...
private void writeObject(ObjectOutputStream os) throws IOException {
os.defaultWriteObject();
for (Element e = erstes; e != null; e = e.next) {
os.writeUTF(e.daten);
}
os.writeUTF("");
}
...
}
Über die Methode writeObject() erhält die Liste die Möglichkeit anzugeben, wie sie gespeichert werden möchte. Hierzu bekommt sie den ObjectOutputStream übergeben, der gerade für die Serialisierung verwendet wird. Anstatt die Elemente mit allen Referenzen zu schreiben, werden einfach die Elemente in der richtigen Reihenfolge gespeichert. Das Ende der Liste wird hier (ebenfalls wieder recht naiv) durch einen leeren String markiert – in einer echten Implementierung müsste man hier etwas intelligenter vorgehen.
Damit die für die Serialisierung nötigen Metadaten geschrieben werden, ist es sinnvoll am Anfang der writeObject()-Methode os.defaultWriteObject() aufzurufen.
Damit die vorhandenen Referenzen auf den Anfang und das Ende der Liste ignoriert werden, müssen diese transient gesetzt werden.
private void readObject(ObjectInputStream is)
throws IOException, ClassNotFoundException {
is.defaultReadObject();
String string;
while ((string = is.readUTF()).length() > 0) {
add(string);
}
}

Analog zum Schreiben muss die Klasse über readObject() festlegen, wie die Daten gelesen werden sollen. Hier werden ebenfalls die Elemente der Liste linear eingelesen und über die add()-Methode wieder zu einer Liste im Speicher zusammengestellt.
Wie man deutlich sieht, hat sich die Datenmenge drastisch gegenüber der Standard-Serialisierung reduziert.
readResolve()
- Serialisierung führt zu einer tiefen Kopie, da ganze Objektgeflechte kopiert werden
- Singletons sollen aber nicht mehrfach vorhanden sein
- Mit
readResolve()kann eine Objekt sich selbst während der Deserialisierung ersetzen - Mit
writeReplace()kann es während der Serialisierung eingreifen
Da die Serialisierung nicht weiß, welche Objekte Singletons sein sollen, werden diese genauso geschrieben und gelesen, wie alle anderen Objekte auch. Dies hat aber zur Folge, dass nach der Serialisierung und Deserialisierung eines Singletons, dieses plötzlich zweimal vorhanden ist.
Für diesen und ähnliche Fälle besteht die Möglichkeit für Klassen, über writeReplace() die eigene Instanz bei der Serialisierung zu ersetzen und bei readResolve() dasselbe bei der Deserialisierung zu machen.
Beispiel: readResolve()
public class TrueSingleton implements Serializable {
private static final TrueSingleton instanz = new TrueSingleton();
private TrueSingleton() {
// keine Instanzen zulassen
}
public static TrueSingleton getInstance() {
return instanz;
}
}
ObjectOutputStream os = new ObjectOutputStream(
new FileOutputStream("/tmp/singleton.ser"));
os.writeObject(TrueSingleton.getInstance());
os.close();
ObjectInputStream is = new ObjectInputStream(
new FileInputStream("/tmp/singleton.ser"));
TrueSingleton singleton = (TrueSingleton) is.readObject();
is.close();
System.out.println(singleton == TrueSingleton.getInstance()); // --> false
Das Beispiel zeigt, dass man von der Klasse TrueSingleton durch Serialisierung mehr als ein Objekt erzeugen kann. Dies widerspricht aber der Idee eines Singletons und sollte vermieden werden.
public class TrueSingleton implements Serializable {
private static final TrueSingleton instanz = new TrueSingleton();
public static TrueSingleton getInstance() {
return instanz;
}
private Object readResolve() throws ObjectStreamException {
return TrueSingleton.instanz;
}
}
Durch die Methode readResolve() hat ein Objekt die Möglichkeit, sich selbst nach der Deserialisierung zu ersetzen. Anstatt des gelesenen Objektes wird das Objekt verwendet, dass von der Methode zurückgegeben wird.
serialVersionUID
- Die Java-Laufzeit berechnet für jede Klasse eine spezielle ID um Kompatibilität bei der Serialisierung sicherzustellen, die serialVersionUID
- Diese ID ist stark abhängig von diversen Faktoren
- Man sollte daher für serialisierbare Klassen eine eigene serialVersionUID angeben
public class Mitarbeiter implements Serializable {
private static final long serialVersionUID = 8248054551788936332L;
...
}
Serialisierte Objekte können längere Zeit in dieser Form verharren, bevor sie wieder deserialisiert werden. Währenddessen kann es passieren, dass sich die Klasse verändert, zu der das Objekt gehört. Da die Klasse nicht serialisiert wird, können (persistentes) Objekt und Klasse sich unterscheiden und nicht mehr zusammenpassen. Um dies zu verhindern, erzeugt Java für jede Kasse eine Versionsnummer, die bei der Serialisierung zusammen mit dem Objekt abgespeichert wird. Diese Nummer verändert sich bei jeder Änderung an den Attributen der Klasse. Wird ein Objekt geladen, dessen Versionsnummer nicht zur Klasse passt, bricht die Deserialisierung ab.
Um den Mechanismus beeinflussen zu können, kann jede Java-Klasse ein privates, statisches Attribut namens serialVersionUID angeben, das dann anstatt der von Java berechnete Versionsnummer verwendet wird. Jetzt können die Programmierer:innen entscheiden, welche Änderungen an der Klasse dazu führen sollen, dass sich die Versionsnummer ändert. Solange man sie unverändert lässt, beschwert sich Java nicht und lädt die Objekte.
Es gilt gemeinhin als guter Stil, das Attribut zu setzen, um den Automatismus von Java auszuschalten. Andernfalls kann es passieren, dass gespeicherte Objekte nicht mehr geladen werden können, obwohl die Änderungen an der Klasse eigentlich unkritisch waren.