Bäume
Baum
Ein Baum ist ein abstrakter Datentyp, der eine hierarchische Struktur darstellt, die aus Knoten (nodes) und Kanten (edges) zwischen ihnen besteht. Ein Baum hat einen Wurzelknoten (root node), von dem aus alle anderen Knoten erreicht werden können. Jeder Knoten (außer der Wurzel) hat genau einen Elternknoten und kann 0 oder mehrere Kinderknoten haben.
- (innerer) Knoten: Knoten mit Eltern und Kindern
- Kante: Verbindungen zwischen den Knoten
- Wurzel: Knoten ohne Eltern
- Blatt: Knoten ohne Kinder
Methoden
insert: fügt einen neuen Knoten in den Baum eindelete: entfernt einen Knoten aus dem Baumsearch: sucht nach einem bestimmten Knoten im Baumtraverse: durchläuft alle Knoten im Baum in einer bestimmten Reihenfolge (z. B. Tiefensuche, Breitensuche)
Arten (Beispiele)
- Binäre-Bäume: zwei Kinder pro Knoten
- AVL-Bäume: Balancierter Binärbaum
- B-Bäume: Max und Min für die Anzahl der Kinder pro Knoten
Es gibt verschiedene Arten von Bäumen, wie z. B. binäre Bäume, AVL-Bäume, B-Bäume und Entscheidungsbäume. Jeder Typ hat seine eigenen Eigenschaften und Anwendungen.
- Binäre Bäume haben die Eigenschaft, dass jeder Knoten höchstens zwei Kinder hat. Sie werden häufig in Such- und Sortieralgorithmen verwendet.
- AVL-Bäume sind eine spezielle Art von binären Bäumen, die immer ausgeglichen sind und eine gute Balance zwischen Zeit- und Speicherkomplexität bieten.
- B-Bäume haben eine variable Anzahl von Kindern pro Knoten. Jeder Knoten (außer der Wurzel und der Blätter) hat mindestens eine bestimmte minimale Anzahl von Kindern und eine maximale Anzahl.
Ein Beispiel für die Verwendung eines Baumes wäre ein Suchalgorithmus, bei dem ein binärer Suchbaum verwendet wird, um schnell nach einem bestimmten Element in einer großen Menge an Daten zu suchen.
Binärbaum
Beispiel: Arithmetischer Ausdruck
Ausdruck (3 + 4) * 5 + (2 * 3) als Baum
Arithmetische Ausdrücke können als Binärbäume dargestellt werden, weil sie eine Hierarchie von Operationen enthalten. In einem arithmetischen Ausdruck haben bestimmte Operationen Vorrang vor anderen, z. B. die Multiplikation vor der Addition. Ein Binärbaum kann diese Hierarchie effizient darstellen, indem er Operationen als Knoten und Operanden als Kinderknoten speichert. Die Operationen an den Knoten bestimmen die Art der Berechnung, die auf den Operanden durchgeführt werden soll, und die operanden werden rekursiv berechnet, bis man die endgültigen Werte erhält. Auf diese Weise kann man arithmetische Ausdrücke in einer natürlichen Weise als Baumstruktur darstellen und berechnen.
Binärbaum
Jeder Knoten eines Binärbaums kann durch eine einfache Datenstruktur abgebildet werden, die neben den Daten (data) die jeweils linken und rechten Kindknoten speichert (left und right).
class Node {
int data;
Node left;
Node right;
public Node(int item) {
key = item;
left = right = null;
}
}
Die Klasse für den Binärbaum enthält nur den Wurzelknoten und die Methoden, um auf dem Baum zu arbeiten.
public class BinaryTree {
Node root;
...
}
Binärbaum: Niveaus
Ein Binärbaum kann in Niveaus unterteilt werden. Ein Niveau bezieht sich auf die Tiefe eines Knotens in dem Baum. Der Wurzelknoten befindet sich auf Niveau 0, die Kinder des Wurzelknotens auf Niveau 1, deren Kinder auf Niveau 2 und so weiter. Jeder Knoten auf einem höheren Niveau ist ein Vaterknoten für die Knoten auf einem niedrigeren Niveau. Die maximale Anzahl der Niveaus in einem Binärbaum ist durch die Tiefe des Baumes bestimmt, die die Länge des längsten Pfads von der Wurzel zu einem Blattknoten ist.
Traversieren eines Baumes
Es gibt drei Hauptwege, um durch die Knoten eines Binärbaumes zu durchlaufen: Tiefensuche (engl. Depth-First Search, DFS), Breitensuche (engl. Breadth-First Search, BFS) und die Symmetrische Reihenfolge (engl. In-Order traversal).
Durchlaufen von Knoten (Traversierung)
- Tiefensuche
- Pre-Order: Knoten → linke Teilbaum → rechte Teilbaum
- In-Order: linke Teilbaum → Knoten → rechte Teilbaum
- Post-Order: linke Teilbaum → rechte Teilbaum → Knoten
- Breitensuche: alle Knoten auf demselben Niveau von links nach rechts besucht, dann wird auf das nächste Niveau gewechselt. Auch Level-Order genannt.
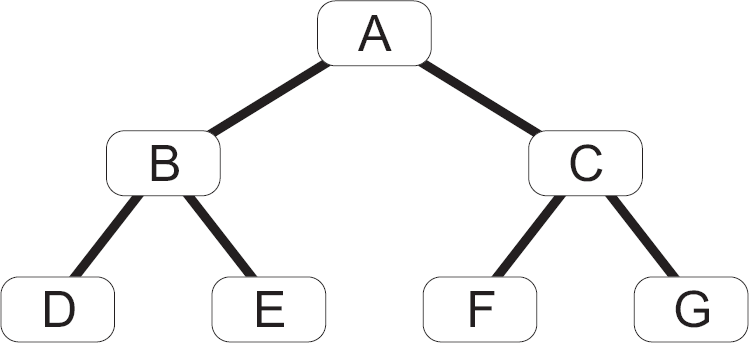
| Durchlauf | Reihenfolge |
|---|---|
| Pre-Order | A, B, D, E, C, F, G |
| In-Order | D, B, E, A, F, C, G |
| Post-Order | D, E, B, F, G, C, A |
| Breitensuche | A, B, C, D, E, F, G |
- Tiefensuche: Die Tiefensuche durchläuft den Baum in einer rekursiven Art und Weise, indem zuerst der linke Teilbaum besucht wird, dann der Wurzelknoten und schließlich der rechte Teilbaum. Es gibt drei Arten von Tiefensuche, die man anwenden kann:
- Pre-Order: Der Knoten wird besucht, bevor die Kinder besucht werden.
- In-Order: Der Knoten wird besucht, nachdem der linke Teilbaum besucht wurde und vor dem rechten Teilbaum.
- Post-Order: Der Knoten wird besucht, nachdem die Kinder besucht wurden.
- Breitensuche: Dieser Durchlauf besucht die Knoten eines Baumes in der Reihenfolge ihrer Tiefen. Es beginnt bei der Wurzel und besucht dann die Kinder der Wurzel in der Reihenfolge links, rechts und fährt dann fort, die Kinder der Kinder zu besuchen.
Jeder dieser Durchläufe hat seine eigenen Anwendungen und Vorteile, je nach der Art der Aufgabe, die man lösen möchte. Beispielsweise ist die Tiefensuche (insbesondere die Post-Order-Traversierung) nützlich, wenn man die Freigabe von Speicher auf einem Baum durchführen möchte, da sie es ermöglicht, die Kinder zuerst freizugeben, bevor der Elternknoten freigegeben wird. Die Breitensuche ist nützlich, wenn man alle Knoten auf einer bestimmten Tiefe besuchen möchte oder wenn man den kürzesten Weg zwischen zwei Knoten finden möchte. Die Symmetrische Reihenfolge ist nützlich, wenn man die Elemente in einem Baum sortiert zurückgeben möchte.
Die Tiefensuche lässt sich am einfachsten mit einem rekursiven Algorithmus realisieren.
public void preorder(Consumer<String> f, Node node) {
if (node == null) return;
f.accept(node.data); // Aktion auf dem Knoten ausführen
preorder(f, node.left); // Linker Teilbaum
preorder(f, node.right); // Rechter Teilbaum
}
public void inorder(Consumer<String> f, Node node) {
if (node == null) return;
inorder(f, node.left); // Linker Teilbaum
f.accept(node.data); // Aktion auf dem Knoten ausführen
inorder(f, node.right); // Rechter Teilbaum
}
public void postorder(Consumer<String> f, Node node) {
if (node == null) return;
postorder(f, node.left); // Linker Teilbaum
postorder(f, node.right); // Rechter Teilbaum
f.accept(node.data); // Aktion auf dem Knoten ausführen
}
Bei der Breitensuche bietet sich ein iterativer Algorithmus an, der eine Queue als Hilfsdatenstruktur verwendet, um die Knoten auf derselben Ebene zu sammeln.
public void levelorder(Consumer<String> f) {
var list = new LinkedList<Node>();
list.add(root);
while (!list.isEmpty()) {
Node n = list.pollFirst();
f.accept(n.data); // Aktion ausführen
if (n.left != null) {
list.add(n.left);
}
if (n.right != null) {
list.add(n.right);
}
}
}