Motivation
Wozu braucht man Nebenläufigkeit?
- Ein Webserver soll mehrere Verbindungen gleichzeitig bearbeiten können
- Ein User-Interface soll nicht blockieren, obwohl eine Berechnung im Hintergrund läuft
- Eine Rechtschreibprüfung soll neben dem normalen Editieren des Dokuments ablaufen
- Eine App soll eine Animation anzeigen und gleichzeitig Daten aus dem Netzwerk nachladen
- Ein mathematisches Problem soll auf mehrere CPUs verteilt werden
Viele Probleme kann man nur lösen, wenn man innerhalb eines Programms mehrere parallele oder quasi-parallele Aktionen zulässt. So muss z. B. ein Webserver in der Lage sein, mehrere Benutzeranfragen (requests) parallel zu verarbeitet. Würde man hier keine Parallelität zulassen, könnte er nur eine Anfrage nach der anderen beantworten, was für die Benutzer:innen nicht akzeptabel wäre.
Genauso gibt es viele andere Dinge, die man gerne parallel ausführen möchte, um das Benutzer-Interface der Anwendung ansprechender zu gestalten. Beispiele sind Animationen oder eine Rechtschreibprüfung, die während der Eingabe direkt die Wörter überprüft. Damit hier der/die Benutzer:in durch die Prüfung in seinem Arbeitsfluss nicht beschränkt wird, muss diese parallel laufen.
Ein weiterer Grund für den Einsatz paralleler Programmierung sind Probleme, die auf mehrere CPUs und CPU-Kerne verteilt werden sollen. Moderne Supercomputer bestehen aus tausenden von CPUs und nur die Parallelisierung der Programme erlaubt es deren Rechenleistung auszunutzen. Da Multiprozessorsysteme heute bereits bei Heimcomputern zum Standard gehören, nimmt die Bedeutung der Parallelprogrammierung immer weiter zu.
Moore’s Law
Moores Gesetz (Moore's law) wurde ursprünglich formuliert in „Cramming more components onto integrated circuits“, Electronics Magazine 19 April 1965 und lautet:
Moore, Cramming more components onto integrated circuits", Electronics Magazine 19 April 1965
Es handelt sich dabei natürlich nicht um ein Gesetzt im engeren Sinne, sondern eher um eine Prophezeiung. Interessanterweise ist diese aber bis heute, also nach fast 50 Jahren, immer noch korrekt.
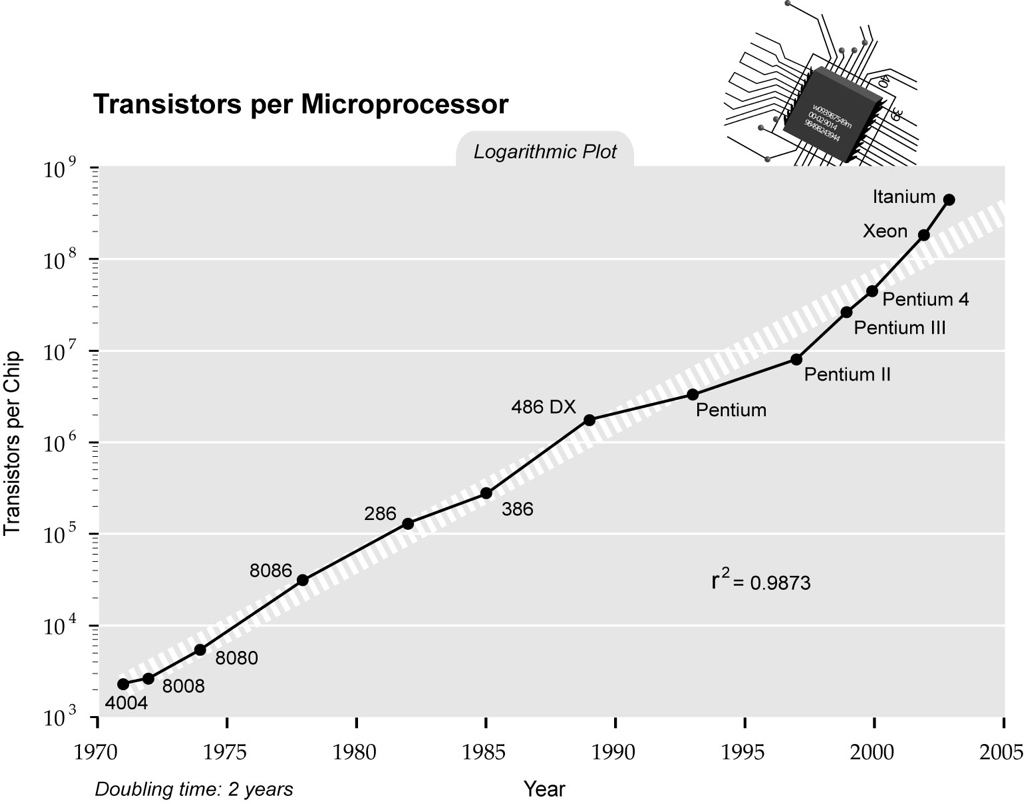
Prozessor Taktraten: 2002
Die zusätzlichen Transistoren, die in den Schaltkreisen zur Verfügung standen, wurden primär dazu genutzt, die Taktraten der Prozessoren zu steigern.
Diese Grafik zeigt eine Vorhersage von Ray Kurzweil aus dem Jahre 2005. Kurzweil hat damals noch geglaubt, dass die Taktraten weiterhin parallel mit der Anzahl der Transistoren steigen. Diese Vorhersage hat sich nicht bewahrheitet, wie wir heute wissen, da durch die Taktraten der Energieverbrauch der Prozessoren ebenfalls steigt und Bereiche erklommen hat, die als nicht mehr akzeptabel gelten. Insofern haben wir im Jahre 2010 nicht die 10 GHz-Prozessoren gesehen, die Kurzweil 2005 vorhergesagt hat.
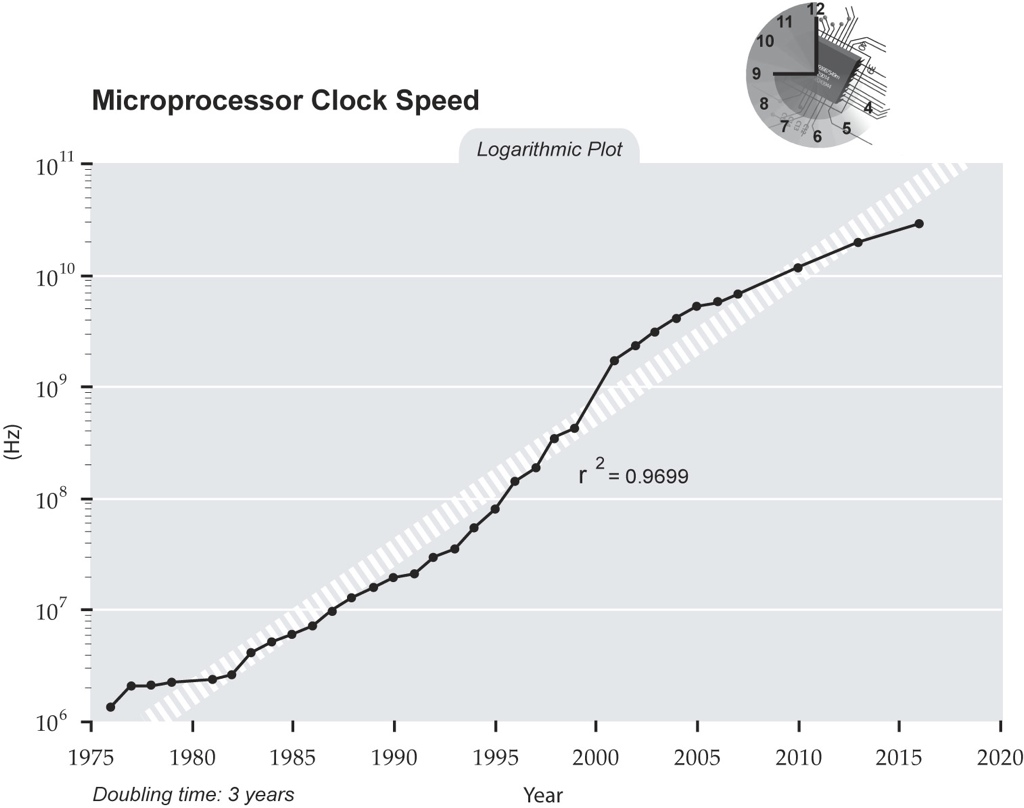
Prozessor Taktraten: 2007
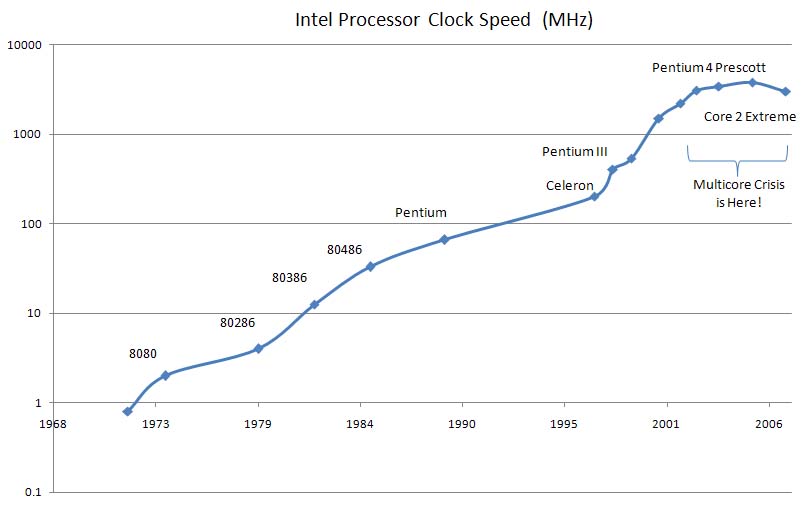
Die tatsächlichen Taktraten der Prozessoren stagnieren seit Mitte der 2000 Jahre. Die zusätzlichen Transistoren fließen daher nicht mehr in höhere Takte, sondern in mehr Prozessorkerne innerhalb eines Chips. Ein moderner Prozessor enthält also auf einem Chip mehrere vollkommen unabhängige Recheneinheiten und besteht eigentlich aus vielen Prozessoren; diese werden als Kerne (cores) bezeichnet. Deshalb spricht man auch von Multi-Core-Prozessoren.
Nebenläufigkeit
- Man unterscheidet zwischen Threads (Fäden) und Prozessen
- Wichtige Begriffe
- Prozesse
- Native Threads, Betriebssystem-Threads
- Green-Threads, User-Level Threads
- Fibers, Co-Routinen
- Scheduling und Scheduler (preemtiv, kooperativ)
Ein Scheduler (Scheduler = Steuerprogramm; vom englischen schedule für „Zeitplan“) ist eine Arbitrationslogik, die die zeitliche Ausführung mehrerer Prozesse (oder Threads) in Betriebssystemen regelt. Scheduler kann man grob in unterbrechende (präemptiv) und nicht unterbrechende (non preemptive) (manchmal kooperativ genannt) aufteilen. Nicht unterbrechende Scheduler lassen einen Prozess, nachdem ihm die CPU einmal zugeteilt wurde, solange laufen, bis dieser diese von sich aus wieder freigibt oder bis er blockiert. Unterbrechende Scheduler teilen die CPU von vornherein nur für eine bestimmte Zeitspanne zu und entziehen dem Prozess diese daraufhin wieder. Quelle: Wikipedia
Thread versus Prozess
- Prozesse
- getrennte Adressräume (getrennter Heap)
- Kommunikation nur über Inter Process Communication (IPC)
- kann einen oder mehrere Threads enthalten
- schwergewichtig
- eigene Ressourcen (geöffnete Dateien, Sockets, Speicher etc.)
- Threads
- gemeinsamer Adressraum (gemeinsamer Heap)
- getrennte Stacks
- Kommunikation über den gemeinsamen Speicher
- leichtgewichtiger als Prozesse
Programme werden vom Betriebssystem als Prozesse ausgeführt. Prozesse sind aus Sicherheitsgründen vollständig voneinander isoliert und haben eigene Ressourcen. Vor allem ist der Speicher von Prozessen vollständig getrennt, d. h. ein Prozess kann nicht auf den Speicher eines anderen Prozesses zugreifen. Prozesse können daher nur über den Umweg des Betriebssystems miteinander in Kontakt treten. Die Technik hierzu nennt man Interprozess-Kommunikation (interprocess communication) IPC. Beispiele für IPC sind Sockets, Pipes und Shared Memory. Wegen der vollständigen Isolation sind Prozesse relativ schwergewichtig, d. h. das Starten und die Verwaltung von Prozessen benötigt relativ viele Ressourcen.
Innerhalb eines Prozesses gibt es einen oder mehrere Threads, die man sich als Ausführungspfade vorstellen kann. Im Gegensatz zu Prozessen sind Threads leichtgewichtiger, d. h. sie lassen sich mit deutlich weniger Aufwand starten und verwalten. Da Threads innerhalb eines Prozesses laufen, haben sie keinen getrennten Heap, sondern teilen sich den Heap und kommunizieren über diesen miteinander. Der Stack ist aber bei Threads getrennt: Jeder Thread hat seinen eigenen Stack.

